Publications
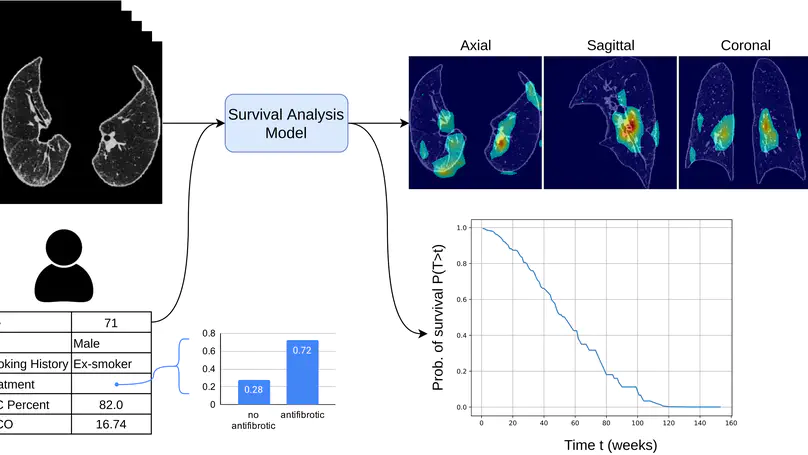
Survival analysis is a valuable tool for estimating the time until specific events, such as death or cancer recurrence, based on baseline observations. This is particularly useful in healthcare to prognostically predict clinically important events based on patient data. However, existing approaches often have limitations; some focus only on ranking patients by survivability, neglecting to estimate the actual event time, while others treat the problem as a classification task, ignoring the inherent time-ordered structure of the events. Additionally, the effective utilisation of censored samples data points where the event time is unknown is essential for enhancing the model’s predictive accuracy. In this paper, we introduce CenTime, a novel approach to survival analysis that directly estimates the time to event. Our method features an innovative event-conditional censoring mechanism that performs robustly even when uncensored data is scarce. We demonstrate that our approach forms a consistent estimator for the event model parameters, even in the absence of uncensored data. Furthermore, CenTime is easily integrated with deep learning models with no restrictions on batch size or the number of uncensored samples. We compare our approach to standard survival analysis methods, including the Cox proportional-hazard model and DeepHit. Our results indicate that CenTime offers state-of-the-art performance in predicting time-to-death while maintaining comparable ranking performance. Our implementation is publicly available at https://github.com/ahmedhshahin/CenTime.
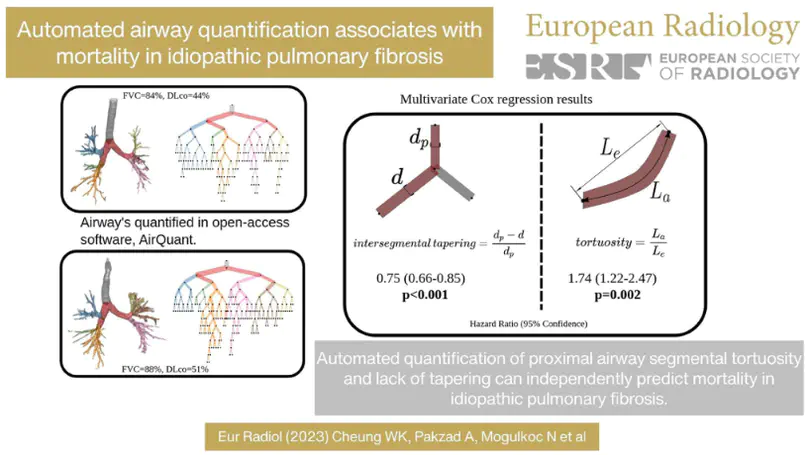
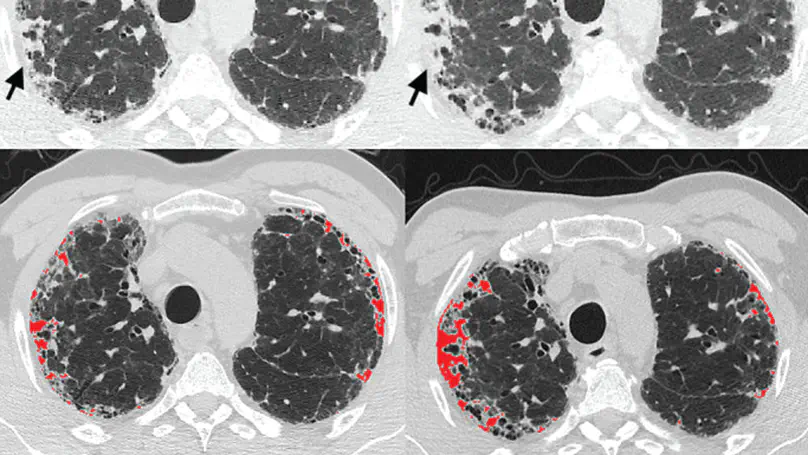
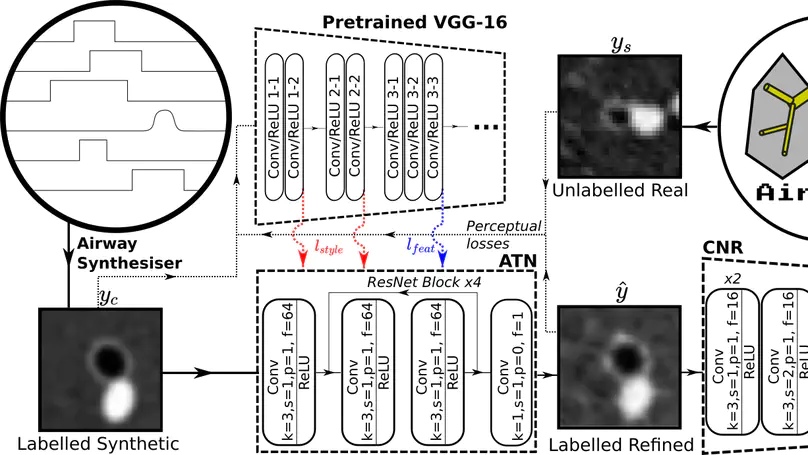
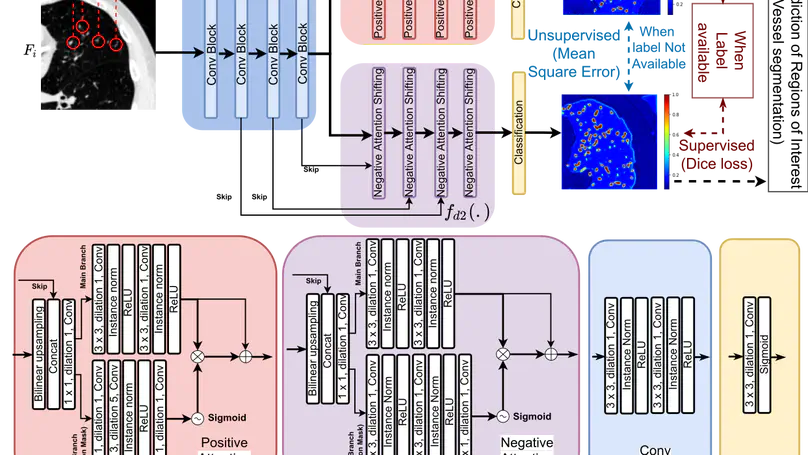
Several chronic lung diseases, like idiopathic pulmonary fibrosis (IPF) are characterised by abnormal dilatation of the airways. Quantification of airway features on computed tomography (CT) can help characterise disease severity and progression. Physics based airway measurement algorithms that have been developed have met with limited success, in part due to the sheer diversity of airway morphology seen in clinical practice. Supervised learning methods are not feasible due to the high cost of obtaining precise airway annotations. We propose synthesising airways by style transfer using perceptual losses to train our model: Airway Transfer Network (ATN). We compare our ATN model with a state-of-the-art GAN-based network (simGAN) using a) qualitative assessment; b) assessment of the ability of ATN and simGAN based CT airway metrics to predict mortality in a population of 113 patients with IPF. ATN was shown to be quicker and easier to train than simGAN. ATN-based airway measurements showed consistently stronger associations with mortality than simGAN-derived airway metrics on IPF CTs. Airway synthesis by a transformation network that refines synthetic data using perceptual losses is a realistic alternative to GAN-based methods for clinical CT analyses of idiopathic pulmonary fibrosis. Our source code can be found at https://github.com/ashkanpakzad/ATN that is compatible with the existing open-source airway analysis framework, AirQuant.